Paper:GroundingDINO 笔记
https://blog.roboflow.com/grounding-dino-zero-shot-object-detection/
GroundingDINO 优点
- 零样本物体检测 — GroundingDINO 擅长检测物体,即使它们不属于训练数据中预定义的类集。这种独特的功能使模型能够适应新的对象和场景,使其具有高度的通用性并适用于各种现实世界的任务。
- 参考表达理解 (REC) — 基于给定的文本描述来识别和定位图像中的特定对象或区域。换句话说,不是检测图像中的人和椅子,然后编写自定义逻辑来确定椅子是否被占用,而是可以使用提示工程来要求模型仅检测有人坐的那些椅子。这要求模型对语言和视觉内容有深入的理解,以及将单词或短语与相应的视觉元素相关联的能力。
- 消除 NMS 等手工设计组件 — Grounding DINO通过消除对非极大值抑制 (NMS)等手工设计组件的需求,简化了目标检测流程。这简化了模型架构和训练过程,同时提高了效率和性能。
GroundingDINO 架构
Grounding DINO 旨在融合DINO和GLIP论文中的概念。DINO 是一种基于 Transformer 的检测方法,提供最先进的目标检测性能和端到端优化,无需 NMS(非极大值抑制)等手工模块。
另一方面,GLIP 侧重于短语基础。此任务涉及将给定文本中的短语或单词与图像或视频中相应的视觉元素相关联,从而有效地将文本描述与其各自的视觉表示联系起来。
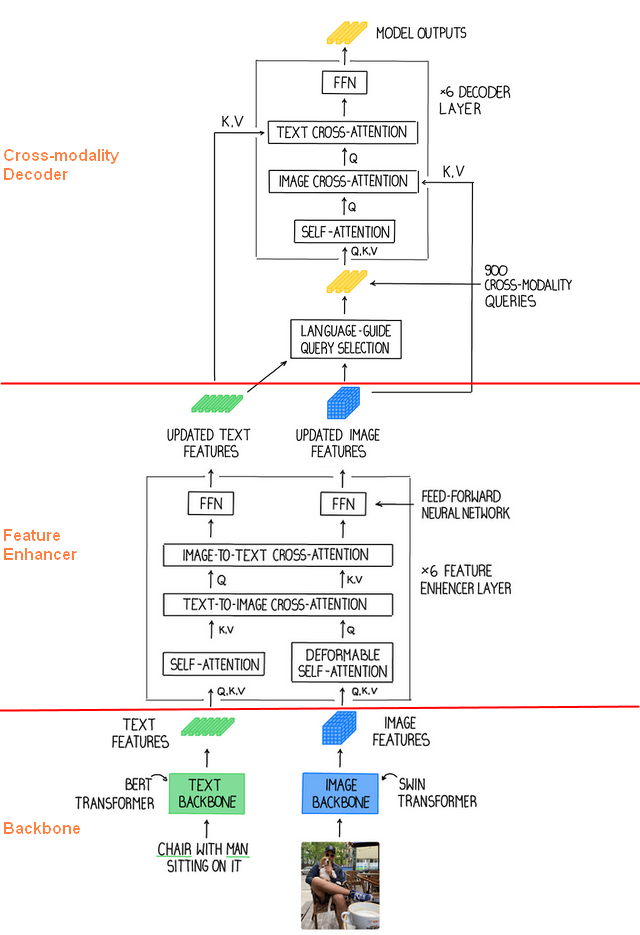
1. 文本主干和图像主干
使用 Swin Transformer 等图像主干提取多尺度图像特征,使用 BERT 等文本主干提取文本特征。

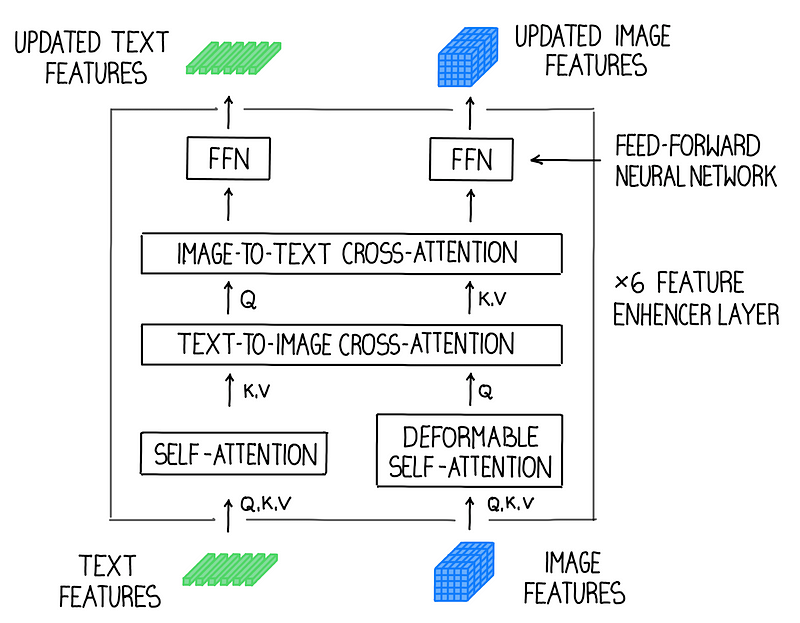
2. 特征增强器
提取普通图像和文本特征后,将它们输入特征增强器中以进行跨模态特征融合。特征增强器包括多个特征增强器层。利用可变形自注意力来增强图像特征,而普通自注意力用于文本特征增强器。
3. 语言引导的查询选择
为了有效地利用输入文本来指导对象检测,语言引导的查询选择模块被设计为选择与输入文本更相关的特征作为解码器查询。
4. 跨模态解码器
开发了跨模态解码器来结合图像和文本模态特征。每个跨模态查询都被馈送到自注意力层、用于组合图像特征的图像交叉注意力层、用于组合文本特征的文本交叉注意力层以及每个跨模态解码器层中的 FFN 层。与 DINO 解码器层相比,每个解码器层都有一个额外的文本交叉注意层,因为需要将文本信息注入到查询中以获得更好的模态对齐。
