ENet 笔记
关键点
- bottleneck
- BN + PRelU
- Spatial Dropout
- 只有 weights,无 bias
一、背景
许多移动应用需要实时语义分割模型。深度神经网络需要大量的浮点运算,导致运行时间长,从而降低了时效性。ENet,相比于 SegNet,在速度块,浮点计算量少,参数少,且有相似的精度。
二、网络结构
整体架构
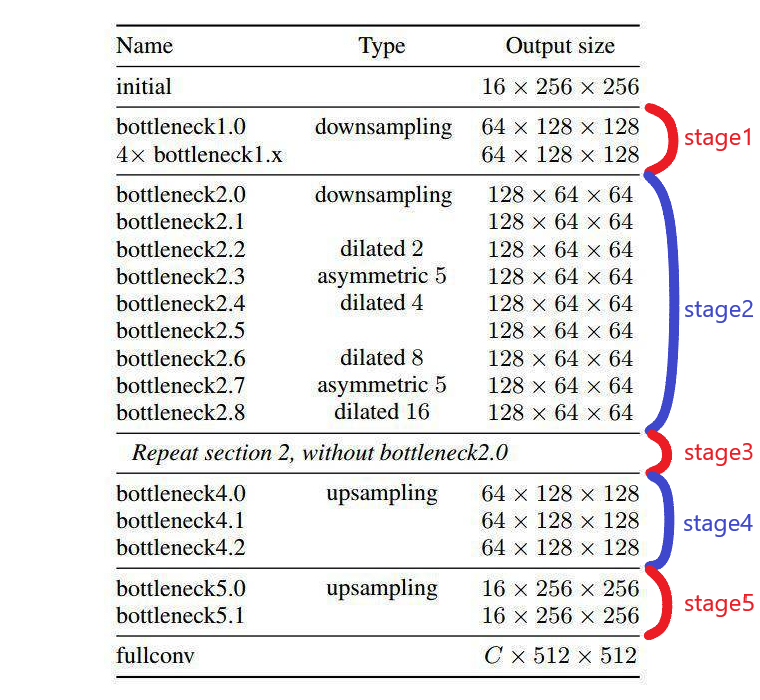
- initial:初始化模块,可大大减少输入的尺寸;
- Stage 1:encoder 阶段。包括 5 个 bottleneck,第一个 bottleneck 做下采样,后面 4 个重复的 bottleneck;
- Stage 2-3:encoder 阶段。stage2 的 bottleneck2.0 做了下采样,后面有时加空洞卷积,或分解卷积。stage3 没有下采样,其他都一样;
- Stage 4~5:属于 decoder 阶段;
初始化模块
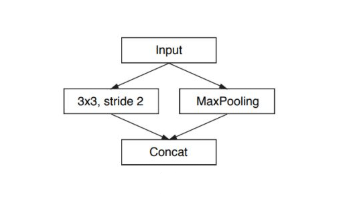
- Conv:3x3,stride 2,num 13
- Maxpooling:2x2,stride 2,num 3
将两边结果 concat 一起,合并成 16 通道,这样可以上来显著减少存储空间。
bottleneck 模块
bottleneck 模块,基于 ResNet 思想。
-
基本的 bottleneck
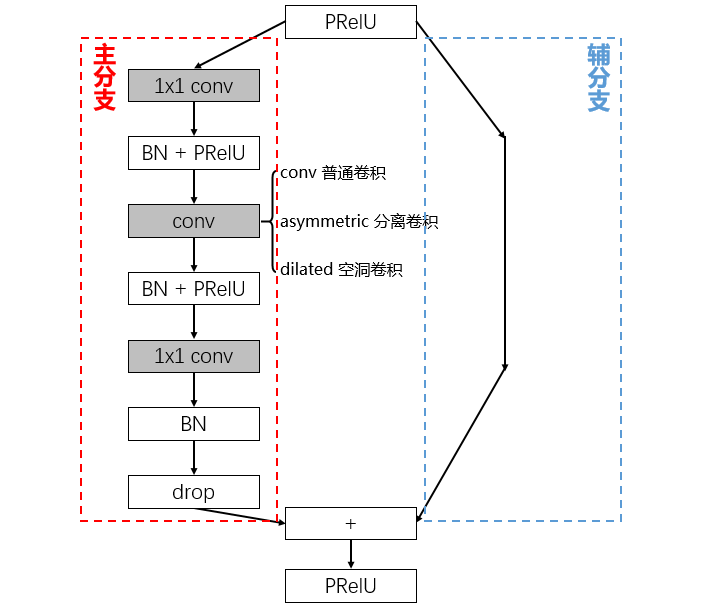
- 第一个 1x1 卷积实现降维;
- 第二个 1x1 卷积实现升维;
- 使用 PReLU 激活函数,ReLU 降低了模型精度(网络层数较少);
- drop 防止过拟合;
- 元素级加法融合;
-
下采样的 bottleneck
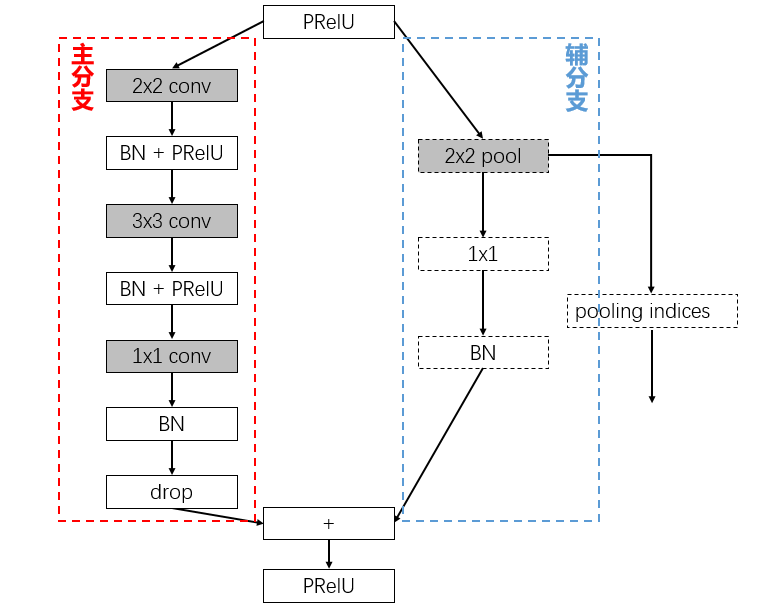
- 2x2 conv 利于信息的保留
- 2x2 pool 降采样提取上下文信息,保存 pooling indices;
- 1x1 卷积升维
-
上采样的 bottleneck

- upsample 采用的是 SegNet 的方法进行上采样,结合下采样中的 pooling indices;
网络细节
- 网络的初始层不应该直接面向分类做贡献,而且尽可能的提取输入的特征。
- Encoder 阶段 Feature map 8 倍下采样;
- Encoder 和 Decoder 不是镜像对称的,网络的大部分实现 Encoder,较少部分实现 Decoder。Encoder 主要进行信息处理和过滤,而 Decoder 上采样编码器的输出,并进行细节微调;
- 整个网络中没有使用 bias,只有 weights。这样可减少内核调用和内存操作,因为 cuDNN 会使用单独的内核进行卷积和 bias 相加。这种方式对准确性没有任何影响;
- 在最后一个(5.0)上采样模块中不使用池化索引,因为输入图片的通道为3,而输出通道数为类别数;
- 网络的最后一个模块是一个裸完全卷积,它占据了处理解码器的大部分时间;
- Spatial Dropout:bottleneck 2.0 之前 p=0.01,之后 p=0.1;
三、训练策略
- 优化器:Adam
- 两阶段训练策略:第一步只训练encoder,对输入做分类;再附加decoder训练
- 学习率:5e-4
- L2权重衰减:2e-4
- batch_size:10
- 使用自定义类别权重(a custom class weighing scheme): $\omega_{class}= \frac{1}{\ln\left(c+p_{class}\right)}$
- 超参数c:1.02