SegNet 笔记
关键点
- encode-decode 结构
- upsampling: pooling indices
一、网络结构

SegNet 是一个 encoder-decoder 的网络结构。SegNet 和 FCN 思路十分相似,只是 Encoder,Decoder(Upsampling)使用的技术不一致。此外 SegNet 的编码器部分使用的是 VGG16 的前 13 层卷积网络(去掉 fc 层),每个编码器层都对应一个解码器层,最终解码器的输出被送入 soft-max 分类器以独立的为每个像素产生类概率。
左边是卷积提取特征,通过pooling增大感受野,同时图片变小,该过程称为 Encoder,右边是反卷积与 upsampling,通过反卷积使得图像分类后特征得以重现,upsampling 还原到图像原始尺寸,该过程称为 Decoder,最后对每一个像素进行 multi-class soft-max 分类,输出不同分类的最大值,得到最终分割图。
二、Decoder
Encoder过程中,通过卷积提取特征,SegNet使用的卷积为same卷积,即卷积后保持图像原始尺寸;在Decoder过程中,同样使用same卷积,不过卷积的作用是为upsampling变大的图像丰富信息,使得在Pooling过程丢失的信息可以通过学习在Decoder得到。SegNet中的卷积与传统CNN的卷积并没有区别。
2.1 pooling indices
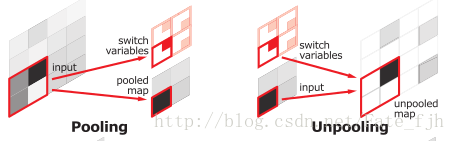
在 SegNet 中的 Pooling 与其他 Pooling 多了一个 index 功能(该文章亮点之一),也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置。

对于上图的 6 来说,6 在粉色 2x2 filter 中的位置为 (1,1)(index 从 0 开始),黄色的 3的 index 为 (0,0)。同时,从网络框架图可以看到绿色的 pooling 与红色的 upsampling 通过 pool indices 相连,实际上是 pooling 后的 indices 输出到对应的 upsampling(因为网络是对称的,所以第1次的pooling对应最后1次的 upsamping,如此类推)。
- 改善了边界划分
- 减少了端到端训练的参数量
- 仅需要少量的修改而可合并到任何编码-解码形式的架构
2.2 upsampling
Upsamping 就是 Pooling 的逆过程(index 在 Upsampling 过程中发挥作用),Upsamping 使得图片变大 2 倍。我们清楚的知道 Pooling 之后,每个filter会丢失了 3 个权重,这些权重是无法复原的,但是在 Upsamping 层中可以得到在 Pooling 中相对 Pooling filter 的位置。所以 Upsampling 中先对输入的特征图放大两倍,然后把输入特征图的数据根据 Pooling indices 放入,下图所示,Unpooling 对应上述的 Upsampling,switch variables 对应Pooling indices。
2.3 对比 FCN
SegNet 在 Unpooling 时用 index 信息,直接将数据放回对应位置,后面再接 Conv 训练学习。这个上采样不需要训练学习 (只是占用了一些存储空间)。反观 FCN 则是用 transposed convolution 策略,即将 feature 反卷积后得到 upsampling,这一过程需要学习,同时将 encoder 阶段对应的 feature 做通道降维,使得通道维度和 upsampling 相同,这样就能做像素相加得到最终的decoder输出。

- 左边是 SegNet 的 upsampling 过程,就是把 feature map 的值 abcd, 通过之前保存的 max-pooling 的坐标映射到新的 feature map 中,其他的位置置零(通过)。
- 右边是 FCN 的 upsampling 过程,就是把 feature map, abcd进行一个反卷积,得到的新的 feature map 和之前对应的 encoder feature map 相加。