Googlenet 笔记
1. Inception模块
Inception架构的主要思想是找出如何用密集成分来近似最优的局部稀疏结。
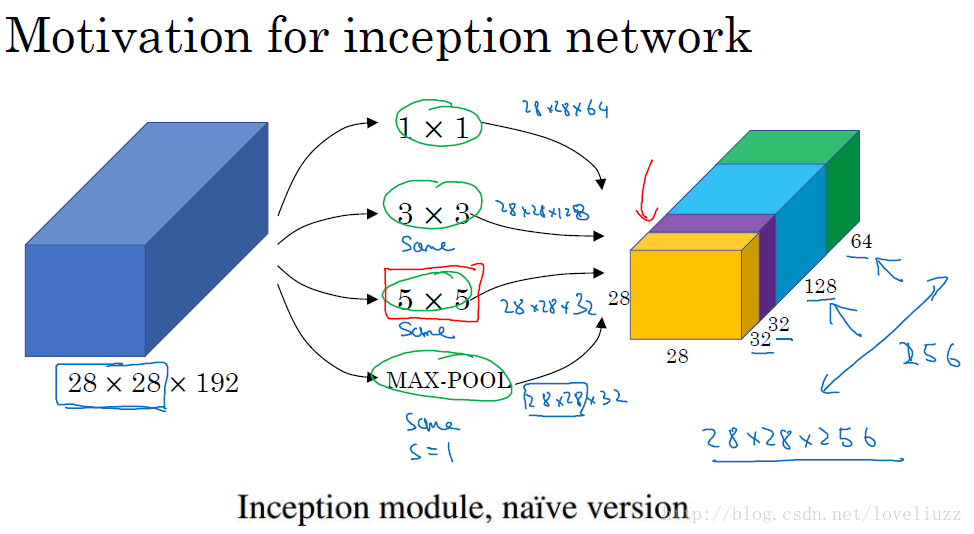
对上图做以下说明:
-
采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
-
之所以卷积核大小采用1*1、3*3和5*5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定padding =0、1、2,采用same卷积可以得到相同维度的特征,然后这些特征直接拼接在一起;
-
文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了pooling。
-
网络越到后面特征越抽象,且每个特征涉及的感受野也更大,随着层数的增加,3x3和5x5卷积的比例也要增加。
1.1 Inception的作用:
代替人工确定卷积层中的过滤器类型或者确定是否需要创建卷积层和池化层,即:不需要人为的决定使用哪个过滤器,是否需要池化层等,由网络自行决定这些参数,可以给网络添加所有可能值,将输出连接起来,网络自己学习它需要什么样的参数。
1.2 naive版本的Inception网络的缺陷:
计算成本。使用5x5的卷积核仍然会带来巨大的计算量,约需要1.2亿次的计算量。

为减少计算成本,采用1x1卷积核来进行降维。 示意图如下:
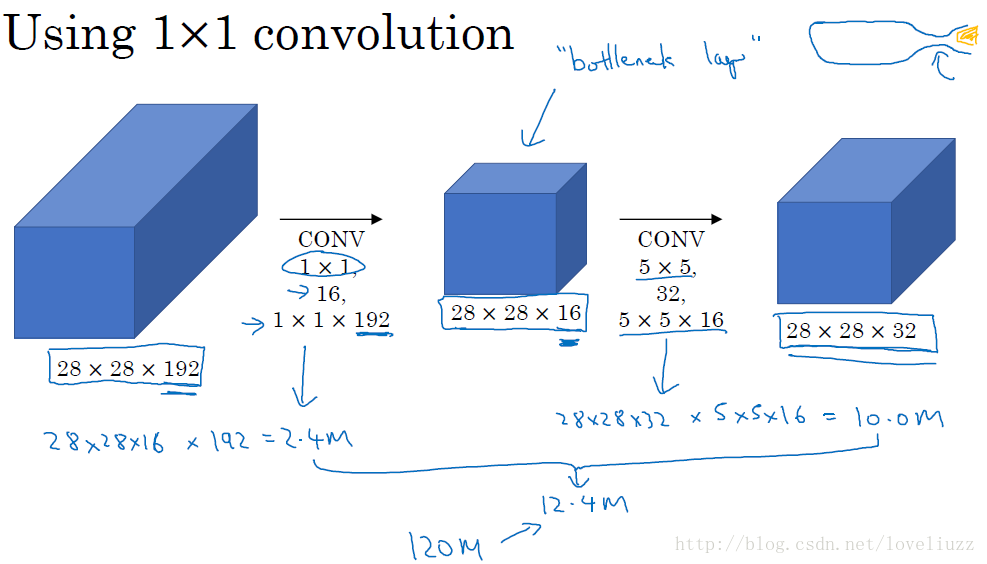
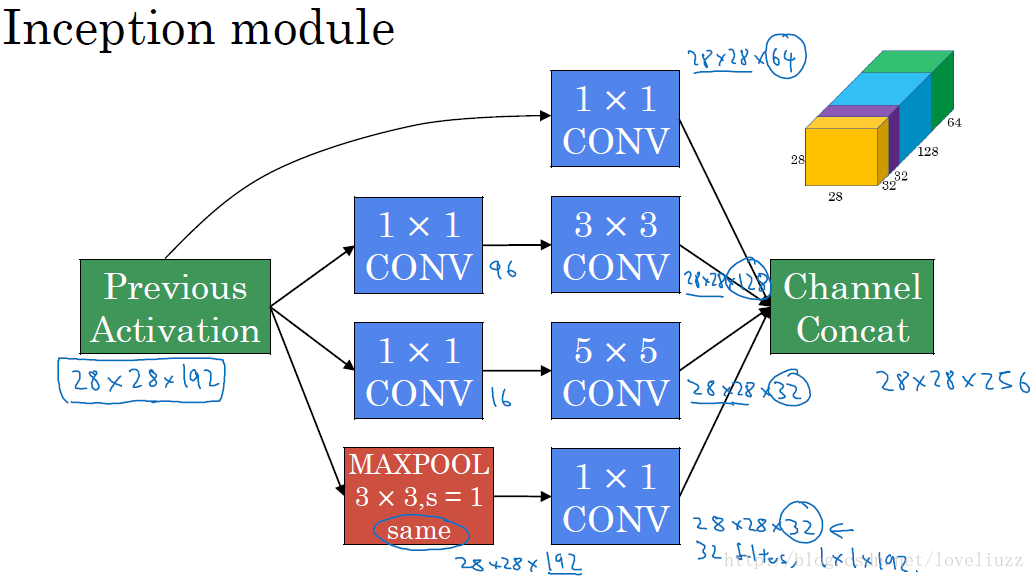
在3x3和5x5的过滤器前面,max pooling后分别加上了1x1的卷积核,最后将它们全部以通道/厚度为轴拼接起来,最终输出大小为28*28*256,卷积的参数数量比原来减少了4倍,得到最终版本的Inception模块:
2. googlenet的主要思想
-
深度,层数更深,文章采用了22层,为了避免上述提到的梯度消失问题,googlenet巧妙的在不同深度处增加了两个loss来保证梯度回传消失的现象。
-
宽度,增加了多种核 1x1,3x3,5x5,还有直接max pooling的,但是如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,
所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用。
3. Inception V1结构
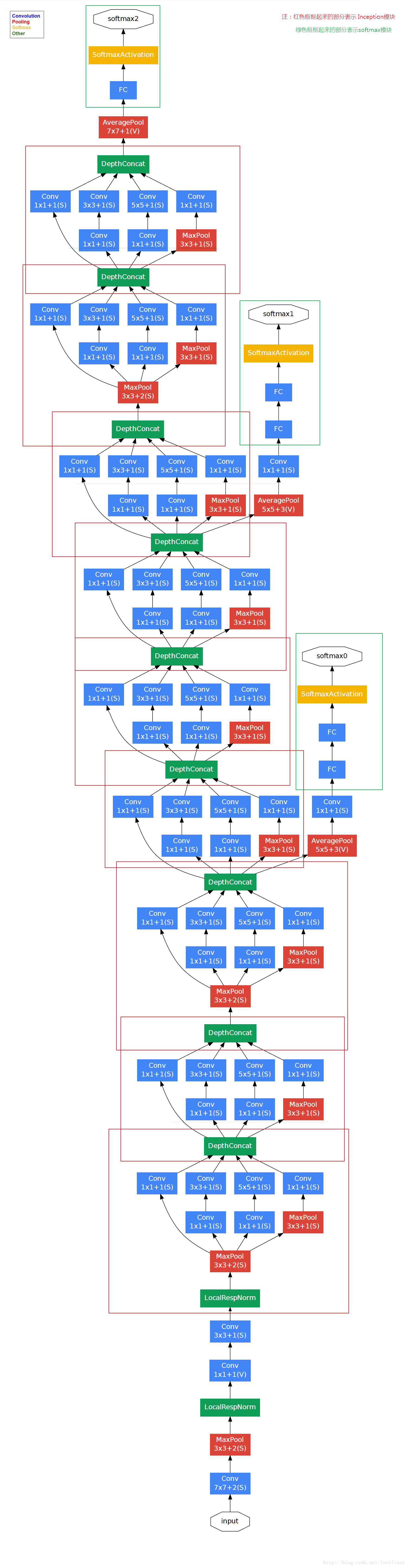
对上图做如下说明:
- 显然GoogLeNet采用了Inception模块化(9个)的结构,共22层,方便增添和修改;
-
网络最后采用了average pooling来代替全连接层,想法来自NIN,参数量仅为AlexNet的1/12,性能优于AlexNet,事实证明可以将TOP1 accuracy提高0.6%。但是,实际在最后还是加了一个全连接层,主要是为了方便finetune;
-
虽然移除了全连接,但是网络中依然使用了Dropout ;
-
为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
文章中说这两个辅助的分类器的loss应该加一个衰减系数,但看caffe中的model也没有加任何衰减。
此外,实际测试的时候,这两个额外的softmax会被去掉。
- 上述的GoogLeNet的版本成它使用的Inception V1结构。
4. Inception V2结构
大尺寸的卷积核可以带来更大的感受野,也意味着更多的参数,比如5x5卷积核参数是3x3卷积核的25/9=2.78倍。为此,作者提出可以用2个连续的3x3卷积层(stride=1)组成的小网络来代替单个的5x5卷积层,这便是Inception V2结构,保持感受野范围的同时又减少了参数量,如下图:
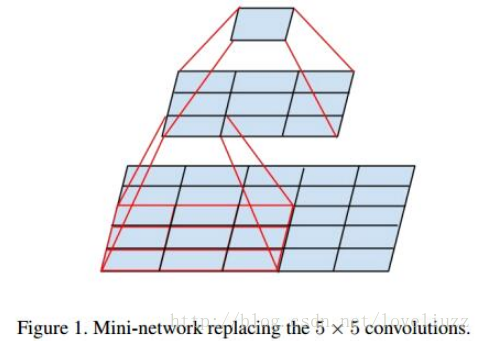


5. Inception V3结构
大卷积核完全可以由一系列的3x3卷积核来替代,那能不能分解的更小一点呢。文章考虑了 nx1 卷积核,如下图所示的取代3x3卷积:于是,任意nxn的卷积都可以通过1xn卷积后接nx1卷积来替代。实际上,作者发现在网络的前期使用这种分解效果并不好,还有在中度大小的feature map上使用效果才会更好,对于mxm大小的feature map,建议m在12到20之间。用nx1卷积来代替大卷积核,这里设定n=7来应对17x17大小的feature map。该结构被正式用在GoogLeNet V2中。


6. Inception V4结构
Inception V4结合了残差神经网络ResNet。