YOLO v2 笔记
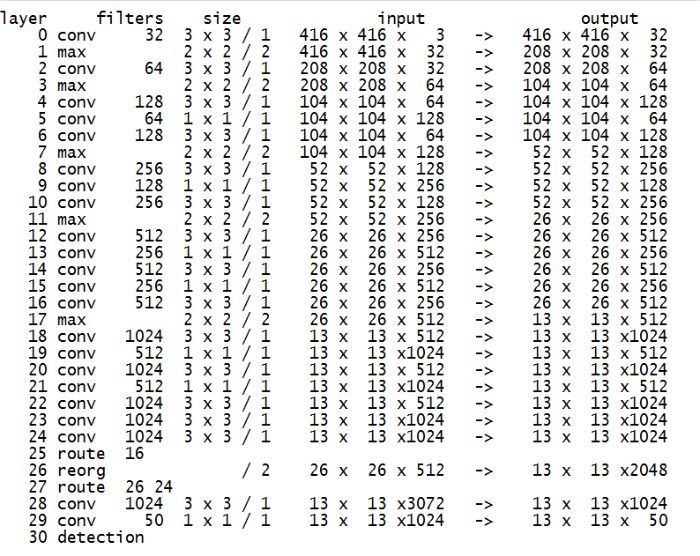
网络结构
相较于 YOLO v1 的改进
-
保留 v1 数据增强的策略的同时,增加了图片180°反转和多尺度训练。
-
添加了 batch normalization,舍弃掉了 dropout,提升模型泛化能力的同时使得模型更容易收敛。
-
首次提出 darknet19,并用全卷积替代全连接,解决了v1全连接的问题,大大减少了参数规模。
-
不再像 v1 一样,直接预测 BBox 的位置和大小,而是受 faster r-cnn 影响,有了 anchor 的概念,从而预测 BBox 相对于 anchor boxes 的偏移量。
-
v2 对 Faster R-CNN 的人为设定先验框方法做了改进,采样 k-means 在训练集 BBox 上进行聚类产生合适的先验框。由于使用欧氏距离会使较大的 BBox 比小的 BBox 产生更大的误差,而 IOU 与 BBox 尺寸无关,因此使用 IOU 参与距离计算,使得通过这些 sanchor boxes 获得好的 IOU 分值。改进的距离评估公式:
使用聚类方法进行选择的优势是达到相同的 IOU 结果时所需的 anchor box 数量更少,使得模型的表示能力更强,任务更容易学习。同时作者发现直接把 faster-rcnn 预测 region proposal 的策略应用于 YOLO 会出现模型在训练初期不稳定。原因来自于预测 region proposal 的中心点相对于 anchor boxes 中心的偏移量较大,不好收敛,公式如下:
由下图可见,将预测值加以 sigmoid 运算,将 region proposal 的中心点牢牢地限定在了 anchor box 的中心点所在的 cell 里,很明显这样偏移量会好学了很多。
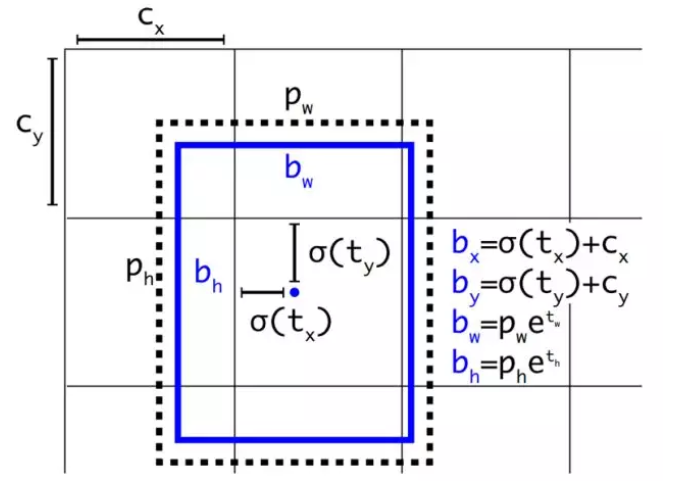
注:
-
$c _ { x } , c _ { y }$ 是当前 cell 左上角的坐标,$p _ { w } , p _ { h }$ 是 anchor box 的长宽,$b _ { w } , b _ { h }$ 是 region proposal 的长宽。
-
输出从 v1 的 S × S × (B × (coordinates + width + height + confidence) + C),变为 v2 的 S × S × B × (coordinates + width + height+ confidence + C)。此时 S=13,B=5,且从 v1 的一个 cell 预测一个类变为了一个 anchor box 预测一类。这是为了解决临近物体检测效果不好问题。
-
损失函数改进,v1 部分提到过,在处理大、小物体上,损失计算设计的不太好,所以 v2 不再简单的对长宽加根号了,而是用 $2 - \mathrm { W } _ { i j ^ { * } } h _ { i j }$ 作为系数加大对小框的损失,$\mathrm { W } _ { i j }$ 和 $\mathrm { h } _ { i j }$ 是第 i 个 cell 的第 j 个 BBox 所匹配到的 ground truth 的长和宽,它们都是相对于原则趋近于 1。可以得出,小物体的惩罚比大物体重。
-
为了获得更多小物体的信息,v2 将第 16 层的 feature map 进行了下采样(26->13),同时将 channel 升维(512->2048),并和第 24 层做了拼接(Concat),作为最终预测的 feature map。