RCNN 笔记
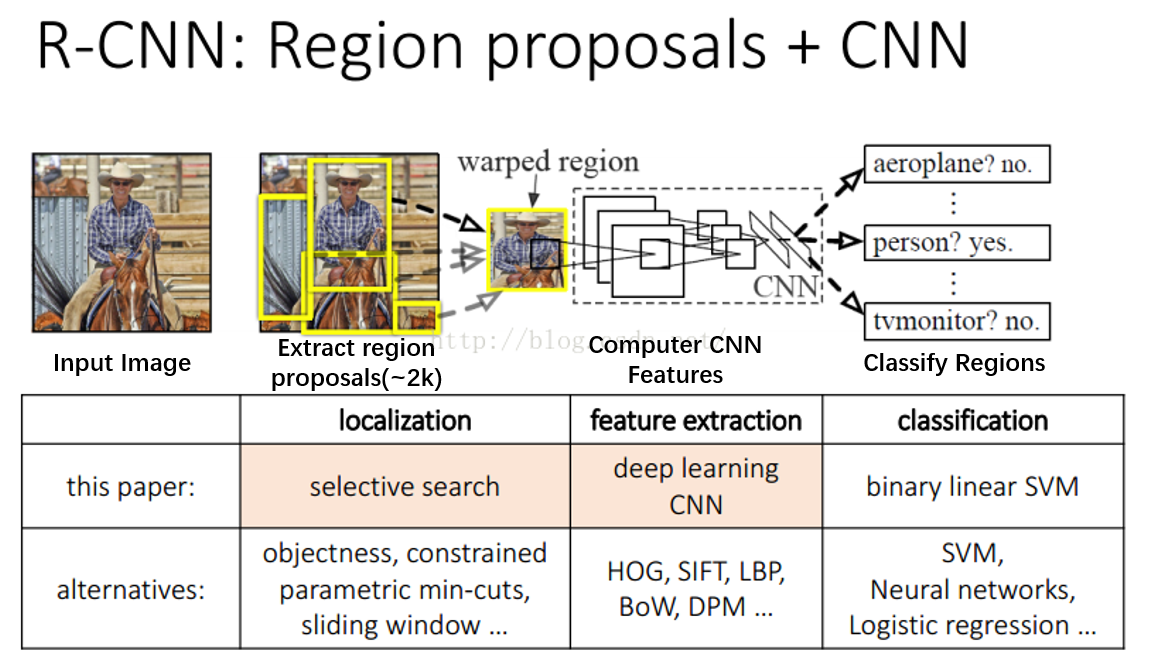
1. 技术路线
Selective Search + CNN + SVMs

2. 算法流程
1. 候选区域生成:利用Selective Search对每张图像生成约2K个候选区域
2. 特征提取:对每个候选区域,使用CNN提取特征
3. 类别判断:特征送入每一类的SVM 分类器,判别是否属于该类
4. 位置精修:使用 Bounding-Box Regression 精细修正候选框位置
3. 候选框搜索——Selective Search
每张图像生成约2000-3000个候选区域。基本思路如下:
-
使用一种过分割手段,将图像分割成小区域;
-
查看现有小区域,合并可能性最高的两个区域。重复直到整张图像合并成一个区域位置, 优先合并以下四种区域:
颜色(颜色直方图)相近的; 纹理(梯度直方图)相近的; 合并后总面积小的----保证合并操作的尺度较为均匀,避免一个大区域陆续“吃掉”其他小区域; 合并后,总面积在其BBOX中所占比例大的----保证合并后形状规则; -
输出所有曾经存在过的区域,所谓候选区域;
4. 特征提取
4.1 预处理
-
使用深度网络提取特征之前,首先把候选区域归一化成同一尺寸227×227。
-
图像缩放:
各向异性缩放:不关心图像的长宽比例,全部归一化为227×227;
各向同性缩放:
-
把Bounding Box的边界扩展成正方形,然后裁剪。超出边界部分就用Bounding Box颜色均值填充。
-
先把Bounding Box裁剪出来,然后用Bounding Box颜色均值填充背景
PS:外扩的尺寸大小,形变时是否保持原比例,对框外区域直接截取还是补灰。会轻微影响性能。
-
4.2 网络结构
基本借鉴Hinton 2012年在Image Net上的分类网络,略作简化:

此网络提取的特征为4096维,之后送入一个4096->1000的全连接(fc)层进行分类。学习率0.01。
4.3 Pre-train
使用ILVCR 2012的全部数据进行训练,输入一张图片,输出1000维的类别标号;

4.4 Fine-running
-
使用上述网络,将最后一层换成4096->21的全连接网络,在PASCAL VOC 2007的数据集(目标数据集)上进行检测训练;
-
使用通过selective search之后的region proposal 作为网络的输入。输出21维的类别标号,表示20类+背景;
-
如果当前region proposal的IOU大于0.5,把他标记为positive,其余的是作为negtive,去训练detection网络。
-
学习率0.001,每一个batch包含32个正样本(属于20类)和96个背景。

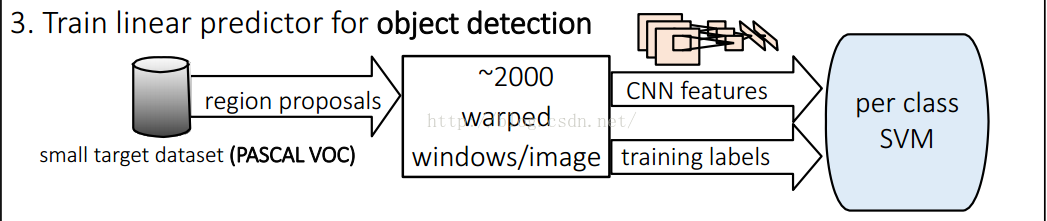
5. 类别判断
对每一类目标,使用一个线性SVM二类分类器进行判别。
CNN得到的4096维特征输入到SVM进行分类,看看这个feature vector所对应的region proposal是需要的物体还是无关的实物(background) 。 排序,canny边界检测之后就得到了我们需要的bounding-box。
由于负样本很多,使用hard negative mining方法。
-
正样本:本类的真值标定框。
-
负样本:考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本
6. 位置精修
6.1 回归器
对每一类目标,使用一个线性脊回归器进行精修。正则项λ=10000。输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。
6.2 训练样本
判定为本类的候选框中,和真值重叠面积大于0.6的候选框。
7. 测试阶段
-
对给定的一张图片,通过Selective Search得到2000个region Proposals,将每个region proposals归一化到227*227;
-
每一个Proposal都经过已经训练好的CNN网络, 得到fc7层的features,4096-dimension,即2000*4096;
-
用SVM分类器(4096*K)得到相应的score,即2000*K;
-
用CNN中pool5的特征,利用已经训练好的权值,得到bounding box的修正值,原先的proposal经过修正得到新的proposal的位置;
-
对每一类别的scores,采用非极大值抑制(NMS),去除相交的多余的框;
-
对于2000*K中的每一列,进行nms;
-
对于特定的这一列(这一类),选取值最大的对应的proposal,计算其他proposal跟此proposal的IOU,剔除那些重合很多的proposal;
-
再从剩下的proposal里选取值最大的,然后再进行剔除,如此反复进行,直到没有剩下的proposal;
-
K列(K类)都进行这样的操作,即可得到最终的bounding box和每一个bounding box对应的类别及其score值;
-