ResNet 笔记
1. 综述
深度学习网络的深度对最后的分类和识别的效果有着很大的影响,所以正常想法就是能把网络设计的越深越好,但是事实上却不是这样,常规的网络的堆叠(plain network)在网络很深的时候,效果却越来越差了。其中原因之一
即是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。 但是现在浅层的网络(shallower network)又无法明显提升网络的识别效果了,所以现在要解决的问题就是怎样在加深网络的情况下又解决梯度消失的问题。
2. 残差模块——Residual bloack
通过在一个浅层网络基础上叠加 y=x 的层(称identity mappings,恒等映射),可以让网络随深度增加而不退化。这反映了多层非线性网络无法逼近恒等映射网络。但是,不退化不是我们的目的,我们希望有更好性能的网络。
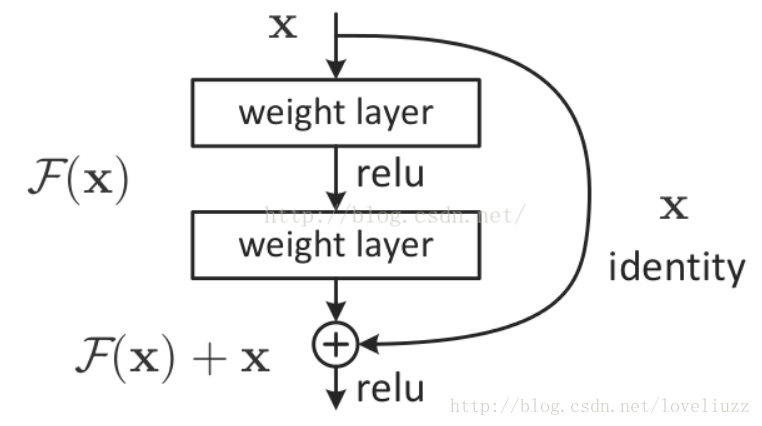
resnet学习的是残差函数F(x) = H(x) - x, 这里如果F(x) = 0, 那么就是上面提到的恒等映射。事实上,resnet是“shortcut connections”的在connections是在恒等映射下的特殊情况,它没有引入额外的参数和计算复杂度。
假如优化目标函数是逼近一个恒等映射, 而不是0映射, 那么学习找到对恒等映射的扰动会比重新学习一个映射函数要容易。残差函数一般会有较小的响应波动,表明恒等映射是一个合理的预处理。


残差模块小结:
非常深的网络很难训练,存在梯度消失和梯度爆炸问题,学习 skip connection 它可以从某一层获得激活,然后迅速反馈给另外一层甚至更深层,利用 skip connection 可以构建残差网络ResNet来训练更深的网络,ResNet网络是由残差模块构建的。
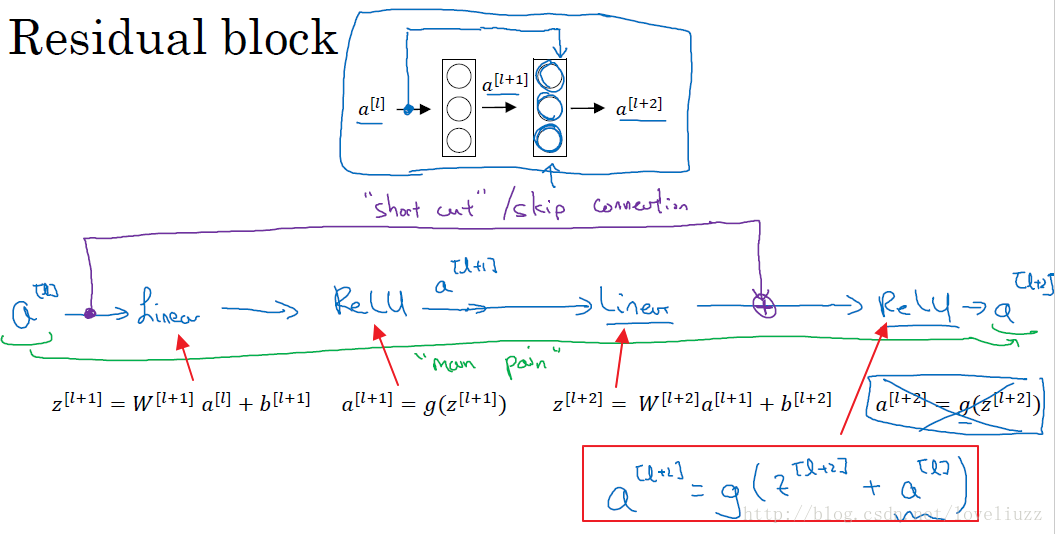
上图中,是一个两层的神经网络,在l层进行激活操作,得到 $a^{\left [ l+1 \right ]}$,再次进行激活得到$a^{\left [ l+2 \right ]}$。由下面公式:
\[a^{\left [ l+2 \right ]} = g\left ( z^{\left [ l+2 \right ]} + a^{\left [ l \right ]}\right )\]$a^{\left [ l+2 \right ]}$ 加上了 $a^{\left [ l \right ]}$ 的残差块,即:残差网络中,直接将 $a^{\left [ l \right ]}$ 向后拷贝到神经网络的更深层,在ReLU非线性激活前面加上$a^{\left [ l \right ]}$,$a^{\left [ l \right ]}$ 的信息直接达到网络深层。使用残差块能够训练更深层的网络,构建一个ResNet网络就是通过将很多.
这样的残差块堆积在一起,形成一个深度神经网络。
3. 残差网络——ResNet
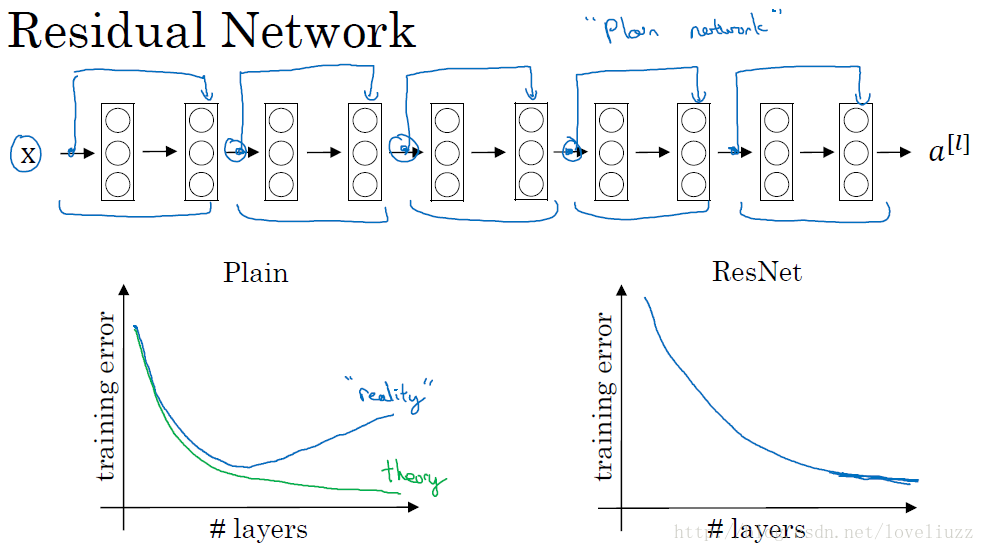
上图中是用 5 个残差块连接在一起构成的残差网络,用梯度下降算法训练一个神经网络,若没有残差,会发现随着网络加深,训练误差先减少后增加,理论上训练误差越来越小比较好。而对于残差网络来讲,随着层数增加,
训练误差越来越减小,这种方式能够到达网络更深层,有助于解决梯度消失和梯度爆炸的问题,让我们训练更深网络同时又能保证良好的性能。
残差网络有很好表现的原因举例:
假设有一个很大的神经网络,输入矩阵为 X,输出激活值为 $a^{\left [ l \right ]}$,加入给这个网络额外增加两层,最终输出结果为 $a^{\left [ l+2 \right ]}$,可以把这两层看做一个残差模块,在整个网络中使用 ReLU 激活函数,所有的激活值都大于等于 0。

对于大型的网络,无论把残差块添加到神经网络的中间还是末端,都不会影响网络的表现。残差网络起作用的主要原因是:It’s so easy for these extra layers to learn the itentity function.
这些残差块学习恒等函数非常容易。可以确定网络性能不受影响,很多时候甚至可以提高学习效率。
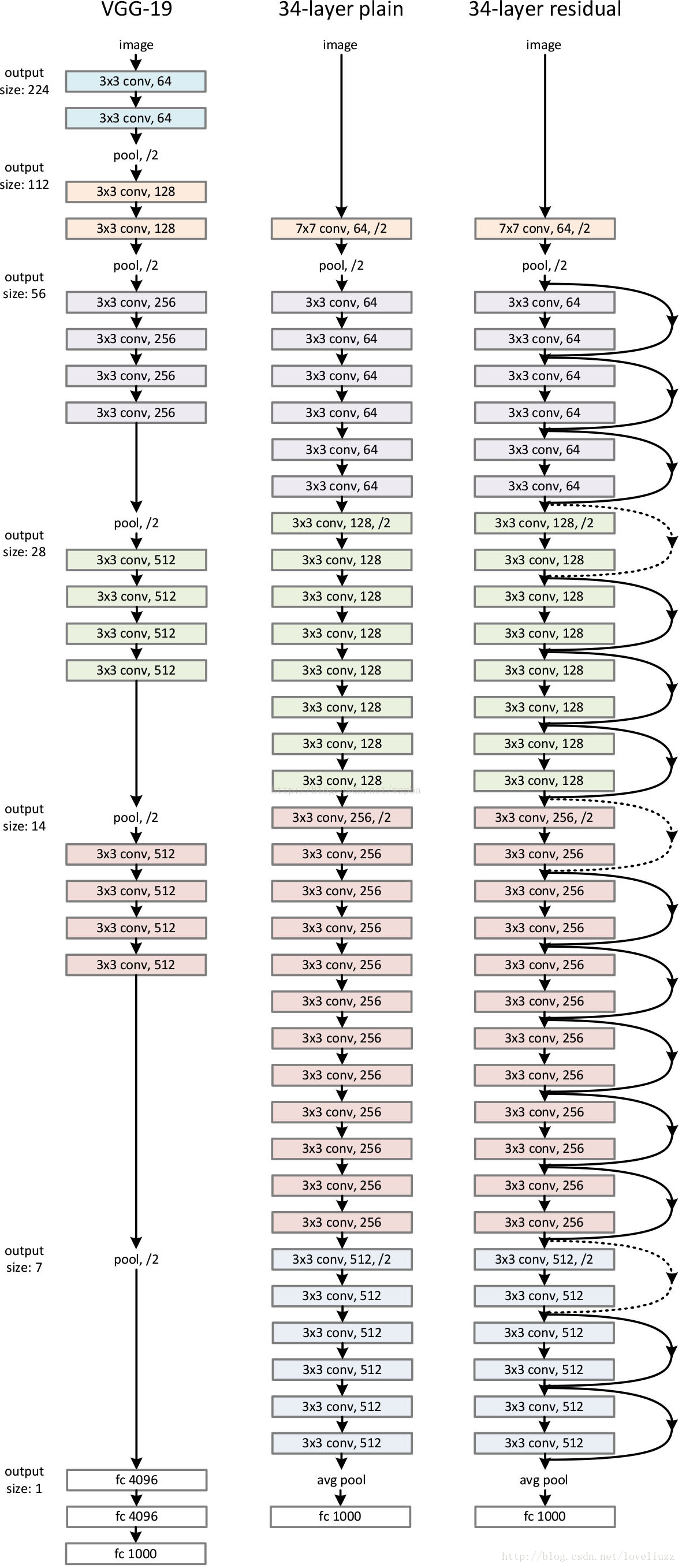

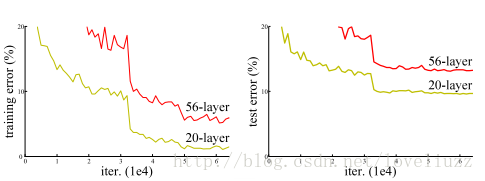
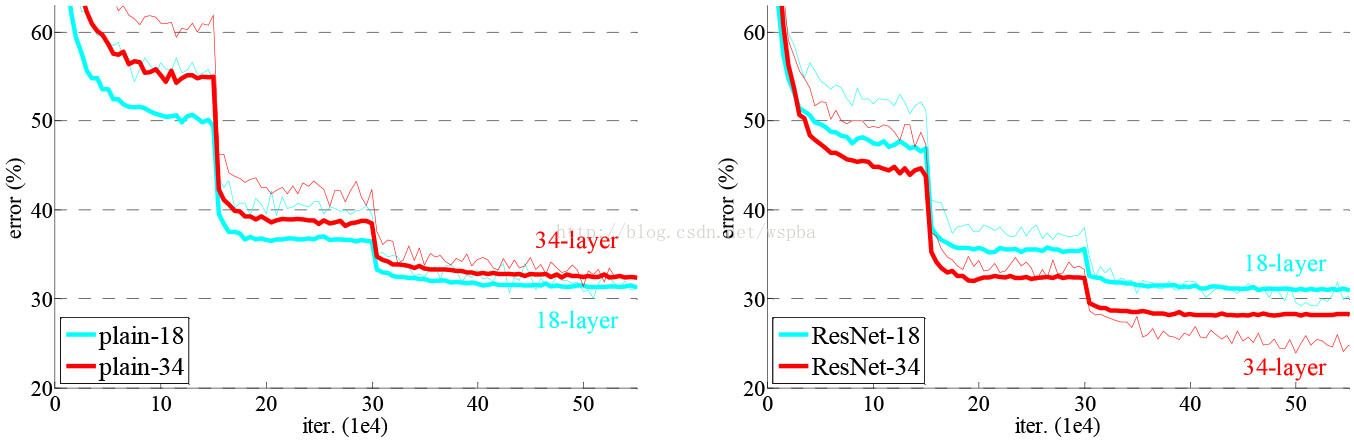
模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
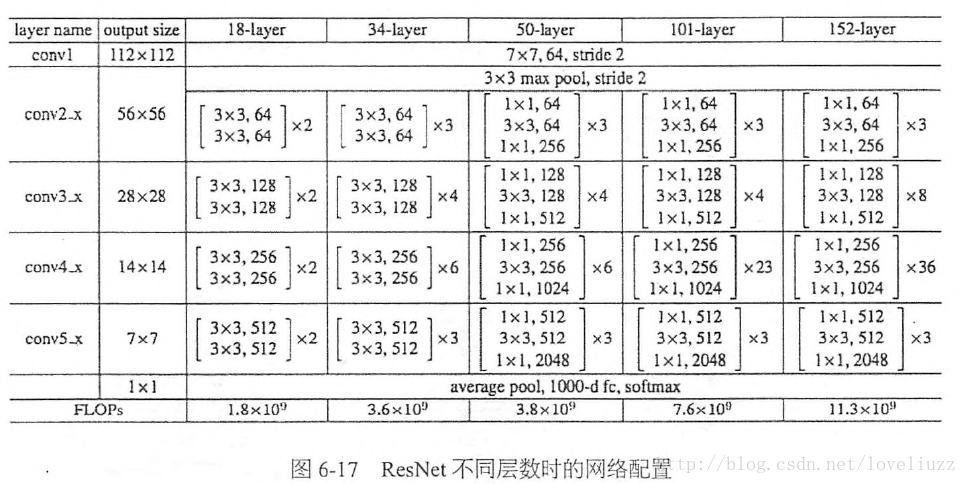
实际中,考虑计算的成本,对残差块做了计算优化,即将两个3x3的卷积层替换为1x1 + 3x3 + 1x1, 如下图。新结构中的中间3x3的卷积层首先在一个降维1x1卷积层下减少了计算,然后在另一个1x1的卷积层下做了还原,既保持了精度又减少了计算量。
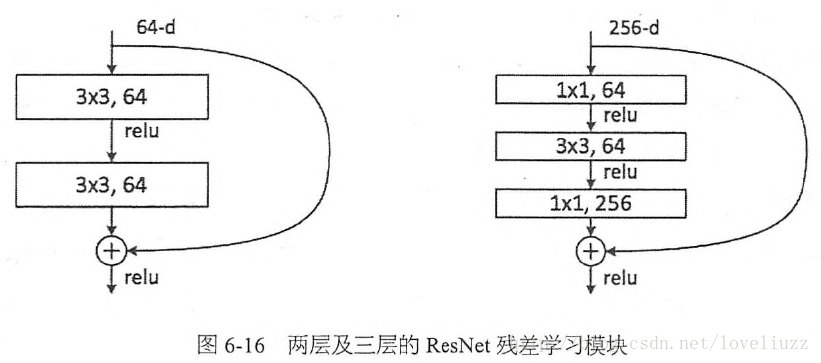

这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的ResNet,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。
这个时候ResNet的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。