YOLO v1 笔记
YOLO v1 是 one-stage 的鼻祖,将目标检测看作为单一的回归问题,直接由图像像素优化得到物体边界位置和分类。
网络结构
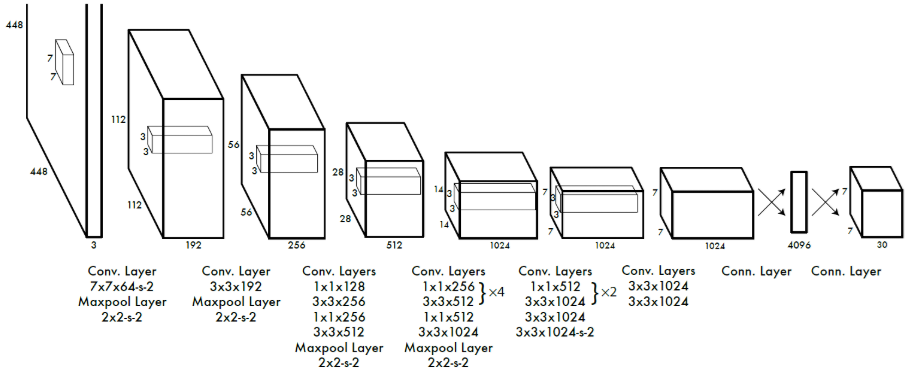
-
来自于 GoogLeNet,用 1x1 和 3x3 卷积核代替 inception modules。
-
由 24 层卷积层接 2 层全连接组成。
模型输入
输入大小
用 ImageNet 数据集做预训练(图片尺寸 224×224 ),做检测模型优化时对输入图片尺寸放大了两倍(图片尺寸 448×448 )。
数据增强
- 饱和度
- 曝光度
- 色调
- 抖动
模型输出
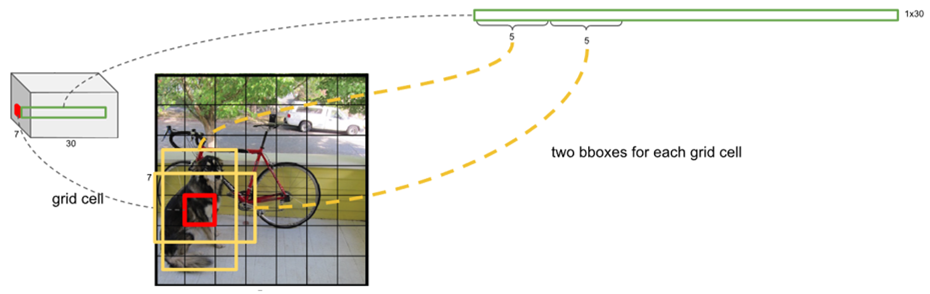
S × S × (B ∗ [x, y, width, height, confidence] + C)
-
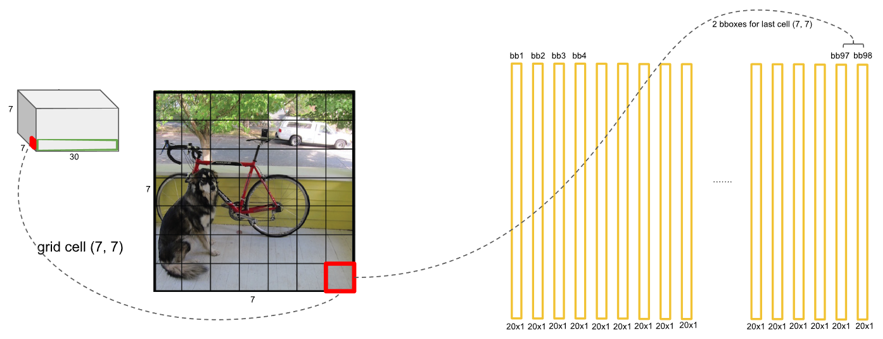
S×S:将图像分成 SxS 个 grid cell,如果某个 object 的中心落在这个网格中,则这个网格就负责预测这个 object;
-
B:每个 grid cell 预测 B 个 bbox;
-
x,y:(x, y)表示 bbox 的中心相对于 grid cell 左上角的 offset;
-
widt,height:宽度和高度是 bbox 相对于整个图像的比例;
-
confidence:表示所预测的 bbox 中是否有目标和这个 bbox 预测的准确度。
-
C:类的个数,其值为 $Pr\left ( Class_{i} Object \right )$ 表示存在的 object 的 grid cell 属于各个种类的概率。所以一个 grid cell 只能预测一种类别的 object。
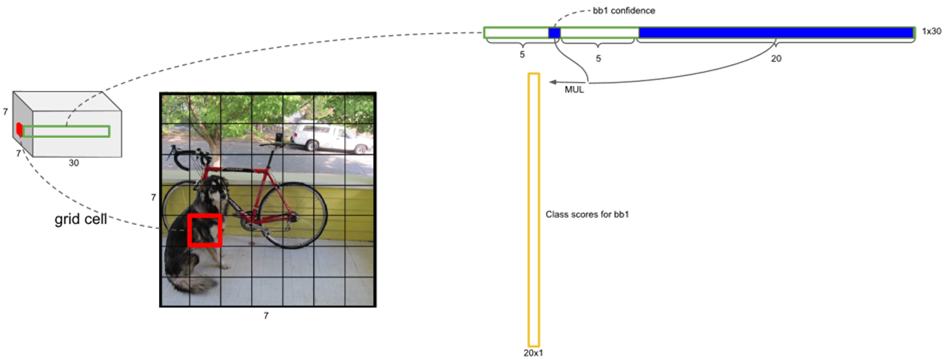
在检测目标时,bbox class-specific confidence score
\[Pr\left ( Class_{i} |Object \right ) \ast Pr\left ( Object \right ) \ast IOU_{pred}^{truth} = Pr\left ( Class_{i} |Object \right ) \ast confidence\] \[Pr\left ( Class_{i} |Object \right ) \text {:grid cell 预测的类别信息}\] \[Pr\left ( Object \right ) 、IOU_{pred}^{truth}\text {:每个 bbox 预测的 confidence}\]YOLO v1:7×7×(2x(4+1)+20)
每个 grid 有 30 维,这 30 维中,8 维是回归 box 的坐标(B=2),2 维是 box 的 confidence,还有 20 维是类别。其中坐标的 x, y 用对应网格的 offset,w、h 用图像的 width 和 height 归一化到 0-1。
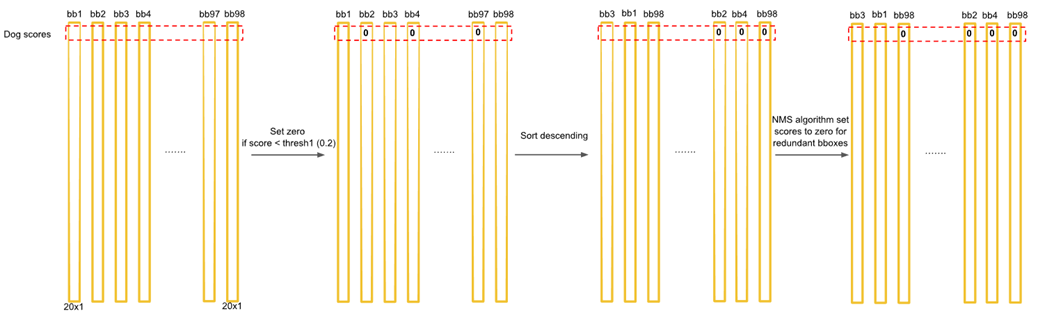
损失函数
粗暴的对所有的项统一用 sum-squared error loss 进行优化。
\[\text {bbox loss:} \qquad \lambda _ { \text { coord } } \sum _ { i = 0 } ^ { S ^ {2} } \sum _ { j = 0 } ^ { B } 1 _ { i j } ^ { o b j } \left[ \left( x _ { i } - \hat { x } _ { i } \right) ^ { 2 } + \left( y _ { i } - \hat { y } _ { i } \right) ^ { 2 } \right] \qquad //中心点损失\] \[\qquad \qquad + \lambda _ { \text {coord} } \sum _ { i = 0 } ^ { S ^ {2} } \sum _ { j = 0 } ^ { B } 1 _ { i j } ^ { o b j } \left[ \left( \sqrt { w _ { i } } - \sqrt { \widehat { w } _ { i } } \right) ^ { 2 } + \left( \sqrt { h _ { i } } - \sqrt { \hat { h } _ { i } } \right) ^ { 2 } \right] \quad //宽高损失\] \[\text {confidence loss:} \qquad + \sum _ { i = 0 } ^ { S ^ {2} } \sum _ { j = 0 } ^ { B } 1 _ { i j } ^ { o b j } \left( C _ { i } - \hat { C } _ { i } \right) ^ { 2 } //含物体的 BB 的 confidence\] \[\qquad \qquad \qquad + \lambda _ { n o o b j } \sum _ { i = 0 } ^ { S ^ {2} } \sum _ { j = 0 } ^ { B } 1 _ { i j } ^ { n o o b j } \left( C _ { i } - \hat { C } _ { i } \right) ^ { 2 } //不含物体的 BB 的 confidence\] \[\text {classification loss:} \qquad \qquad \ + \sum _ { i = 0 } ^ { S ^ {2} } 1 _ { i } ^ { o b j } \sum _ { c \in c l a s s e s } \left( p _ { i } ( c ) - \hat { p } _ { i } ( c ) \right) ^ { 2 } //类别预测\]-
$\mathbb { 1 } _ { i j } ^ { \text { obj } }$:表示第 i 个 cell 里的第 j 个 BBox 是否负责预测这个 object;在计算 loss 时,与 GT 的 IOU 最大的 BBox 负责预测;
-
$\mathbb { 1 } _ { i j } ^ { \text { noobj } }$:不含 object;
-
$\mathbb { 1 } _ { i } ^ { \text { obj } }$:判断是否有物体落在第 i 个 cell 中;如果 cell 中包含有物体的中心,就负责预测该类。
-
$\lambda _ { n o o b j } = 0.5$:防止 overpowering,背景框的数量要远大于前景框,不加以限制,confidence 的值将趋近于零;
-
$\lambda _ { c o o r d } = 5$:为什么这样取值,作者说得很模糊,意思是如果坐标框的系数和类别一样的话显然是不合理的,所以加大了对框的惩罚,但 YOLOv2 和 YOLOv3 改用全卷积网络后这个参数 s 就改为 1 了。
-
$\left[ \left( \sqrt { w _ { i } } - \sqrt { w } _ { i } \right) ^ { 2 } + \left( \sqrt { h _ { i } } - \sqrt { \overline { h } } _ { i } \right) ^ { 2 } \right]$:对宽高都进行开根是为了减少小偏差对小的 bbox 的影响。
小结
-
只有当 grid cell 中有 object 的时候才对 classification error 进行惩罚。
-
只有当某个 box predictor 对某个 ground truth box 负责的时候,才会对 box 的 coordinate error 进行惩罚,而对哪个 ground truth box 负责就看其预测值和 ground truth box 的 IoU 是不是在那个 cell 的所有 box 中最大。
训练细节
Leaky ReLU
- 最后一层使用的是标准的线性激活函数,其他层使用的是 Leaky ReLU f(x)=max(x,0.1x);
- 避免使用 ReLU 的时候有些单元永远得不到激活,在不增加计算法复杂度的前提下提升了模型的拟合能力;
dropout
- 防止过拟合;
- 设置为 0.5,接在第一个 FC 层后;
优化器
- batch = 64;
- 学习率:epoch (0-75) $10^{-2}$, (75-105) $10^{-3}$, (最后 30 个) $10^{-4}$;
- 动量 0.9,衰减为 0.0005;
YOLO v1优点
-
YOLO v1 检测物体非常快。 因为没有复杂的检测流程,YOLO 将目标检测重建为一个单一的回归问题,从图像像素直接到边界框坐标和分类概率,而且只预测 98 个框,YOLO 可以非常快的完成物体检测任务。YOLO 在 Titan X 的 GPU 上能达到 45 FPS。Fast YOLO 检测速度可以达到 155 FPS。
-
YOLO 可以很好的避免背景错误,其它物体检测算法使用了滑窗或 region proposal,分类器只能得到图像的局部信息。YOLO 在训练和测试时,由于最后进行回归之前接了 4096 全连接,所以每一个 Grid cell 对应的预测结果都相当于使用了全图的上下文信息,从而不容易在背景上预测出错误的物体信息。和 Fast-R-CNN 相比,YOLO 的背景错误不到 Fast-R-CNN 的一半。
-
YOLO 可以学到更泛化的特征。 当 YOLO 在自然图像上做训练,在艺术作品上做测试时,YOLO 表现的性能比 DPM、R-CNN 等之前的物体检测系统要好很多。因为 YOLO 可以学习到高度泛化的特征,从而迁移到其他领域。
YOLO v1缺点
-
对邻近物体检测效果差,由于每个 grid cell 仅预测两个框和一个分类,对于 多物体的中心位置落入同一 cell,YOLOv1 力所不及;
-
用全连接的问题在于,虽然获取了全局信息,但是比起1×1卷积来说也丢失了局部细节信息;全连接带来了参数量的巨增;
-
对不常见的长宽比物体泛化能力偏弱,这个问题主要是YOLO没有Anchor的不同s尺度框的设计,只能通过数据去驱动;
-
损失函数的设计问题,对坐标的回归和分类的问题同时用 MSE 损失明显不合理;
-
由于YOLOv1是直接预测的BBox位置,相较于预测物体的偏移量,模型会不太好稳定收敛;