DeconvNet 笔记
关键点
- encoder-decoder 结构
- 反卷积层:deconvolution + relu + upooling,可学习的
- 结合目标检测:把每张图片的不同的 proposal 送入网络,通过聚合得到最后的语义分割结果。
一、FCN 突出的缺点
- 网络的感受野是固定的
那些大于或者小于感受野的目标,就可能被分裂或者错误标记。具体点来说,对于大目标,进行预测时只使用了local information所以可能会导致属于同一个目标的像素被误判为不连续的标签(即不同目标),如下图,左侧为input,中间为ground truth,右侧为result,可见这个大巴由于too large所以被分割成了很多不连续的部分。

而对于小目标来说,经常会被忽略掉,被当作了背景。如下图,左侧为input,中间为ground truth,右侧为result。由于人很远所以在图中面积too small,结果被当作背景了:

- 目标的细节结构常常丢失或者被平滑处理掉
输入 deconvolution-layer的label map太粗糙了(只有16x16),而且 deconvolution 这个步骤在 FCN 这篇文章中做的过于简单了。缺少一个在大量数据上得到训练的deconvolution network 使得准确地重构物体边界的高维非线性结构变得困难。
二、网络结构
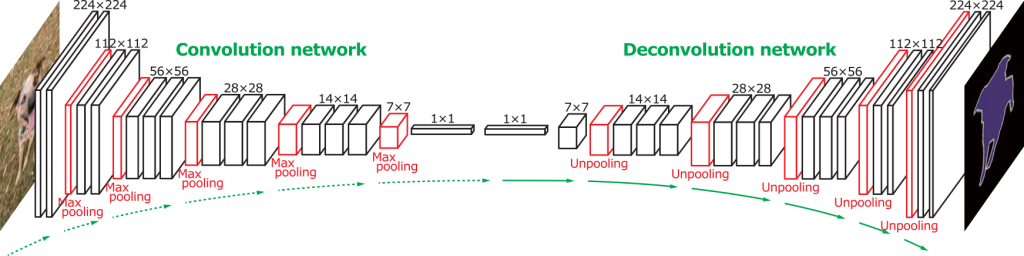
DeconvNet 和 SegNet 的结构非常类似,只不过 DeconvNet 在 encoder 和 decoder 之间使用了 FC 层作为中介,用于增强类别的分类。
- 卷积层:使用VGG-16(去除分类层),把最后分类的全连接层去掉,在适当的层间应用Relu和Maxpooling。增加两个全连接层(1x1卷积)来强化特定类别的投影。
- 反卷积层:卷积层的镜像,包括一系列的 unpooling,deconvolution,Relu 层
- 网络输出:概率图,和输入图像大小相同,表明每个像素点属于预定义类别的概率
三、Unpooling
与 SegNet Upsample 的方法一样。正向 pooling 的时候用 switch variables 记录 Maxpooling 操作得到的activation的位置,在 Unpooling 层利用 switch variables 把它放回原位置,从而恢复成 pooling 前同样的大小。
switch variables 记录的只是 Pooling 的时候被选中的那些值的位置,所以 Unpooling之后得到的 map 虽然尺寸变回来了,但是只是对应的位置有值,其它地方是没有值的。
四、Deconvolution
- 通过deconvolution使稀疏响应图变得稠密。反卷积操作可以实现1个输入,多个输出, 经过反卷积之后会得到扩大且密集的响应图。
- 经过反卷积之后,裁剪(crop)响应图的边界,使其等于unpooling层的输出大小(也是deconvolution层输入的大小)。
- 得到由一系列deconvolution,unpooling layer组成的层级反卷积网络。
五、网络总结
- 该网络实质上将语义分割视作了实例分割问题。
- 将潜在包含对象的子图像作为输入,并以此生成像素级预测作为输出。
- 通过将网络应用于从图像中提取的每个proposal候选区域,并将所有proposal的输出集合到原始图像空间,得到整个图像的语义分割。
较低层网络更多捕捉物体的粗略的外形,像位置,形状,区域等,在高层网络中捕捉更加复杂的模式类别。反池化与反卷积在重构feature map时发挥着不同的作用,反池化通过原feature map中较强像素的位置信息来捕捉 example-specific 结构,进而以一定的像素来构建目标的结构细节,反卷积中的卷积核更倾向于捕捉 class-specific 形状,经过反卷积,虽然会有噪声的影响,但激活值仍会与目标类别进行相关联。该网络将反卷积和反池化结合,获得较好的分割效果。
六、训练方法
- Batch Normalization :将每层的输入分布变为标准高斯分布来减少内协变量,在卷积和反卷积的每一层后添加BN层。避免进入局部最优。
- 两阶段训练:首先基于标签,对含有实例的图片进行裁剪得到包含目标的图片,进一步构成较简单的数据进行预训练,然后使用复杂的数据进行微调,复杂数据集基于简单数据进行构建,proposals 与 groundTruth 的 Iou 大于 0.5 的被选作用于训练。但此做法的弊端是,目标物的位置与尺寸信息与原始数据集出现差别。
七、Inference
- 聚合实例分割图
- 在聚合的时候要抑制一些噪声(如错位),对应所有类别的得分图的像素的最大值或平均值是能够有效获得鲁棒的结果的。
- 用 $g_{i} \in \mathbb{R} ^{W \times H \times C}$ 来代表第 i 个 proposal 的得分图,$W \times H$ 代表这个 proposal 的尺寸,$C$ 代表类别的数量。首先把她放在 $g_{i}$ 的外围有零填充的图像空间上,用下面的 $G_{i}$ 来表示在原始图像尺寸中与 $g_{i}$ 对应的分割图。然后通过像素最大值或平均值来聚合所有 proposals 的输出进而来构建一幅图像的像素级别的类别得分图。
- 将Softmax应用于所得到的聚合映射,得到类别的条件概率映射。最后,再用 fully-connected CRF 得到最终的输出映射,其中一元势能函数是从 pixel-wise 级的条件概率映射中获得的。
- 结合 FCN
- DeconvNet的方法对目标的尺度多样性有较好的适应性,FCN的方法能较好的捕捉背景空间信息。
- 把一张图片输入这两个网络进行单独的处理,然后把两个网络的输出计算均值当作最后的输出,再应用CRF来获得最终的结果。